A dive into CPU caches for those who superficially understand spatial/temporal locality.
Direct Mapped Caches
Recall that a cache line size is the size of a unit of transfer between the DRAM and cache.
Core idea: every word in memory can be mapped onto a single cache line.
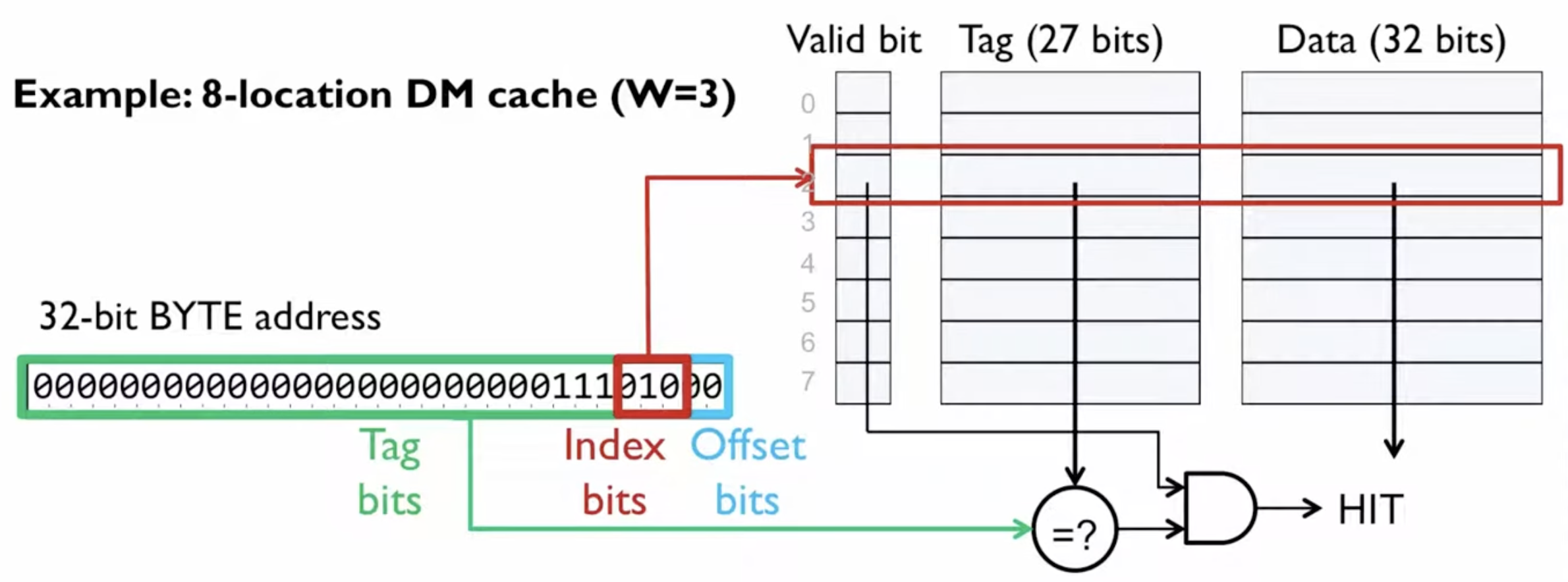
How: Given the setup (8 cache lines, 4-byte cache line size, 1-byte word, 32-bit address)
- Offset: log₂(4) = 2 bits — selects byte within a cache line
- Index: log₂(8) = 3 bits — selects which cache line
- Tag: 32 − 3 − 2 = 27 bits — identifies which memory block is cached
Example: Fetching 0x0E8 from Physical Memory
| Field | Bits | Value | Meaning |
|---|---|---|---|
| Tag | [31:5] | 7 | Which block from memory |
| Index | [4:2] | 2 | Maps to cache line #2 |
| Offset | [1:0] | 0 | Byte 1 within the 4-byte cache line |
So this address looks up cache line 2. If the tag stored there is 7, it’s a hit and byte 1 is returned. Otherwise it’s a miss — the 4-byte block starting at address 0x0E8 is fetched from DRAM into cache line 2.
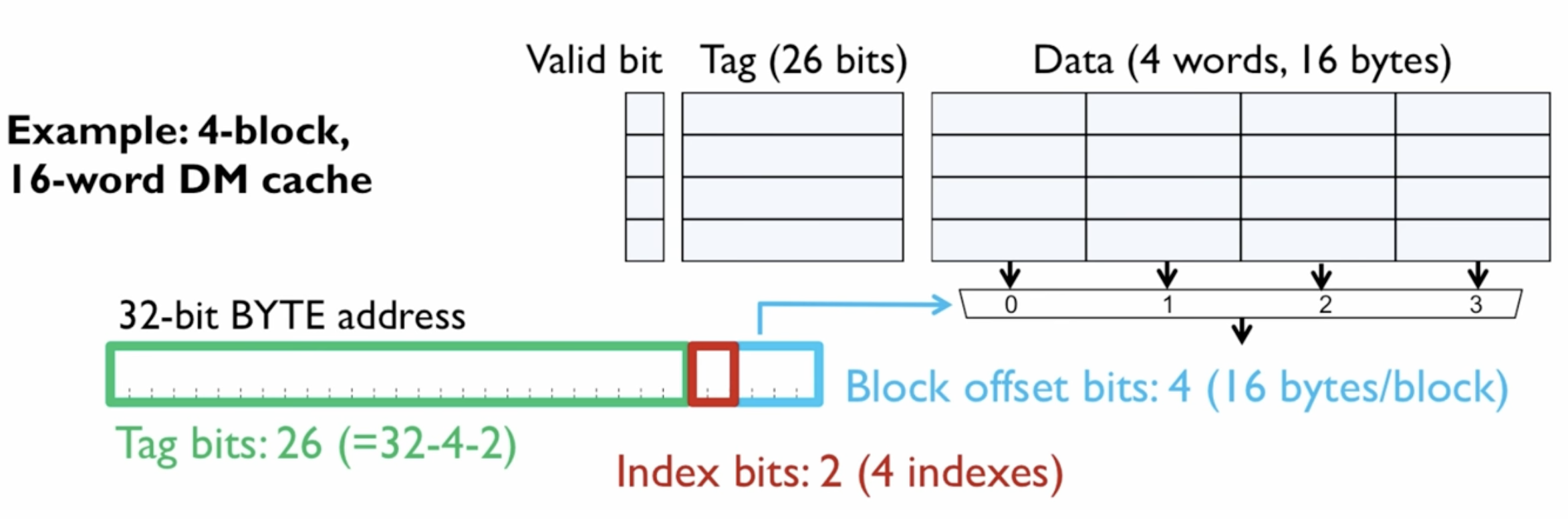
Optimisation: Increasing Block Size
Block size is always a power of 2.
We can take advantage of spatial locality (probability that memory we subsequently access is within the same region of physical memory as the memory we are currently accessing)
This incurs a larger penalty on misses, since it takes longer to transfer the block into cache.
Flaw: Inflexible Mapping
Consider a 1024-line DM Cache with block size = 1 word. If we have a loop in a program that accesses 2 regions in physical memory that correspond to the same cache line, they will be competing for the same cache line slot, leading to repeated misses!
Hit rate = 0%

#include <stdio.h>
#define CACHE_SIZE 1024 // 1024 lines, 1 word per line, so 1024 words = 4096 bytes
int A[CACHE_SIZE];
int B[CACHE_SIZE];
// if A and B happen to be placed exactly CACHE_SIZE apart in memory,
// A[i] and B[i] map to the same cache slot for every i
int main() {
int sum = 0;
for (int i = 0; i < CACHE_SIZE; i++) {
sum += A[i] + B[i]; // A[i] evicts B[i], then B[i] evicts A[i]
// on the next iteration, A[i+1] and B[i+1]
// are also in conflict, same story
}
printf("%d\n", sum);
}The order of access is like so:
access A[i] -> miss, load into slot i
access B[i] -> miss, load into slot i, evicts A[i]
next iteration:
access A[i+1] -> miss, load into slot i+1
access B[i+1] -> miss, load into slot i+1, evicts A[i+1]
Every single access is a miss. The cache is fully occupied the whole time but provides zero benefit.
Fully Associative Caches
The address splits into just two parts - no index bits since there’s no fixed slot assignment:
| ---- Tag bits ---- | Offset bits |Example: 32-bit address, 4-byte cache lines (so 2 offset bits), say 4 cache lines total.
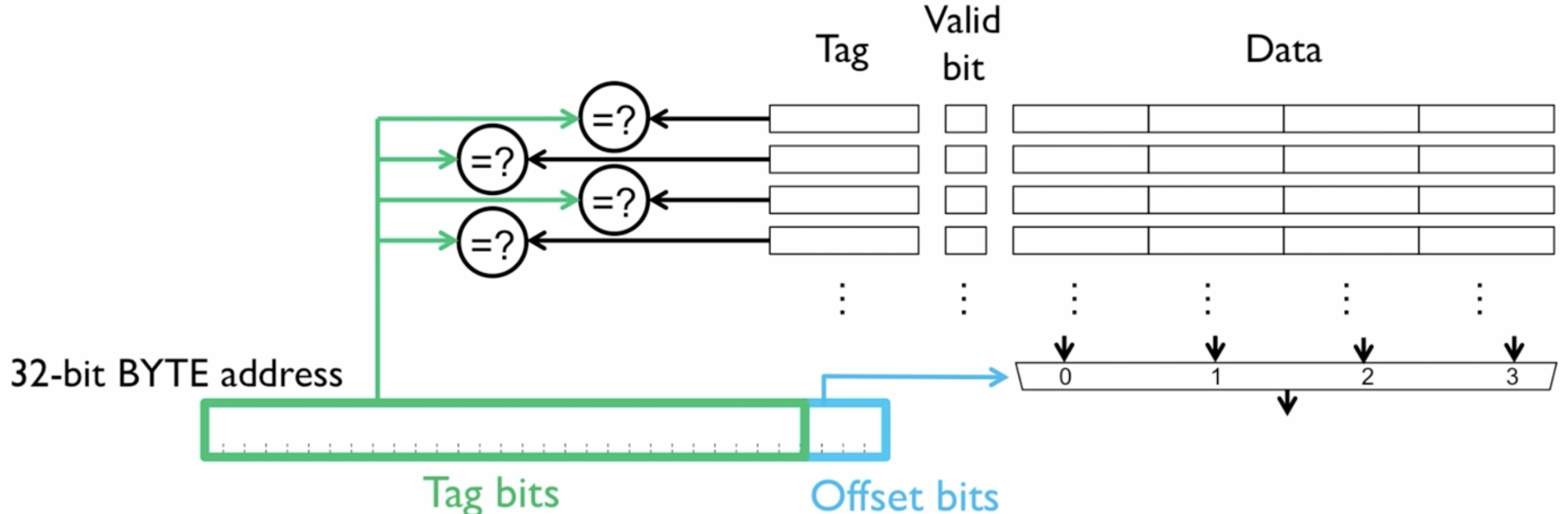
On a read:
e.g. address = 0x00000009
Offset (2 bits): 01 - byte 1 within the cache line
Tag (30 bits): 0x000002
- The tag (0x000002) is broadcast to all 4 comparators simultaneously
- Every cache line checks its stored tag against 0x000002 in parallel
- If any line matches AND its valid bit is 1 - cache hit, use the offset to pick the right byte from that line’s data
- If nothing matches - cache miss, fetch from DRAM, evict some line (LRU etc.), store it anywhere
Why no index? In a direct-mapped or set-associative cache, the index bits tell you exactly which slot(s) to check. Here you just broadcast to everyone and let them all raise their hand simultaneously.
Flaw: Hardware Cost of Comparisons
In an FA Cache with 65,536 entries, every lookup requires 65,536 comparators all firing in parallel. That’s an enormous amount of transistors, and they all need to be fast. You can’t do it iteratively because that would be too slow.
N-Way Set Associative Cache
The N-way set associative cache solves this by restricting where a cache line can live.
Every cache line is associated with a set. That set has only N slots, each of which are connected to a single comparator.
So on a lookup you only need N comparators firing in parallel instead of 65,536.
The tradeoff is that you reintroduce conflict misses: two addresses that map to the same set can now evict each other if all N ways are occupied. But in practice 8-way is enough associativity to eliminate most conflict misses, so you get most of the benefit of fully associative at a tiny fraction of the hardware cost.
Example:
4-Way 8 Set-Associative Cache
- 64 Byte Cache Lines
- 256 Byte Total Cache (4 Ways x 8 Sets x 8 Bytes per line)
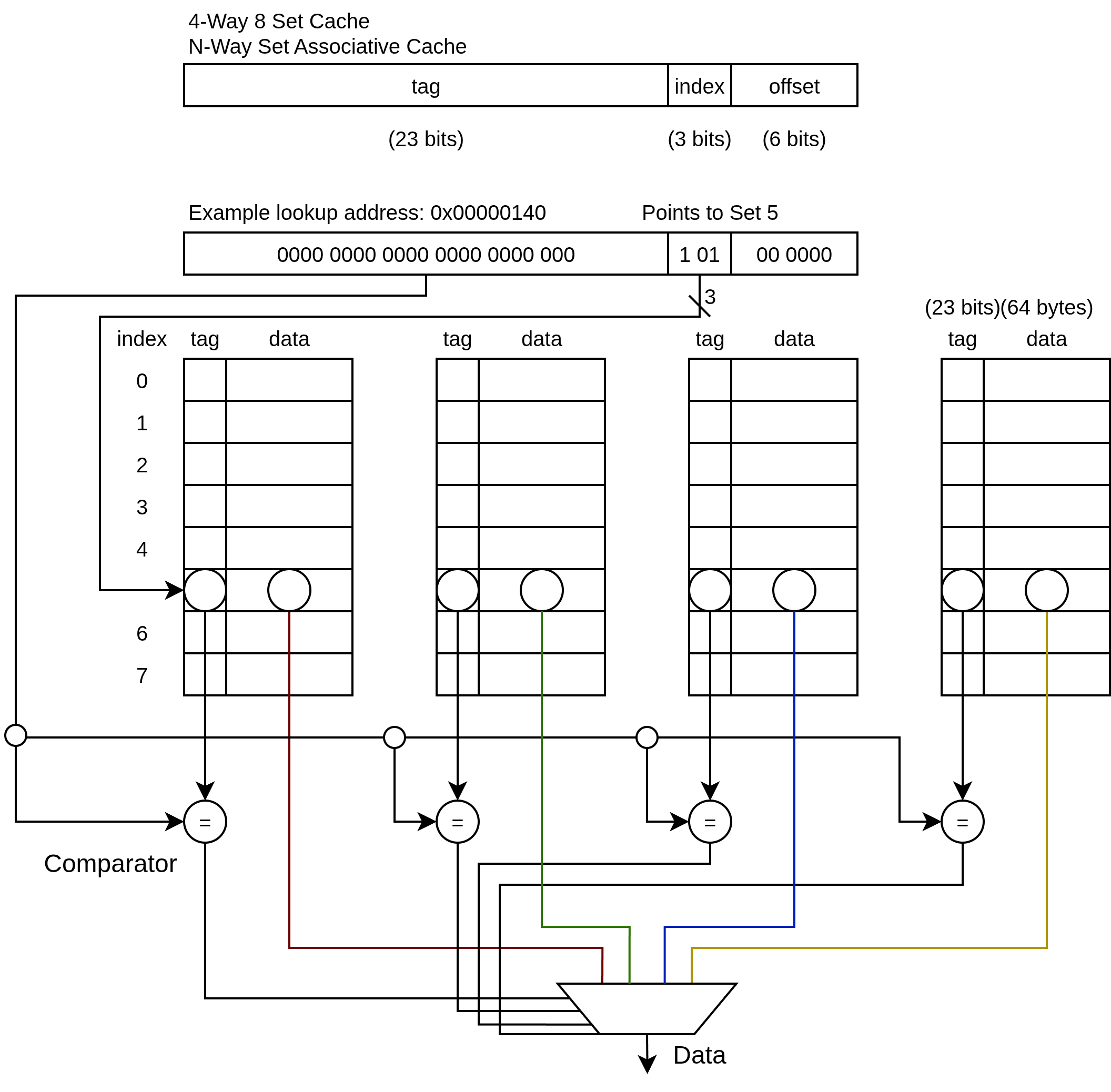
On a read:
- Index bits select set 5 - narrows you to one row across all 8 sets
- The tag is broadcast to all 4 comparators for that set simultaneously
- If any way’s tag matches - hit, use offset to return the right byte
- If no way matches - miss, fetch from DRAM, place in any way within set 5 (e.g. LRU eviction)
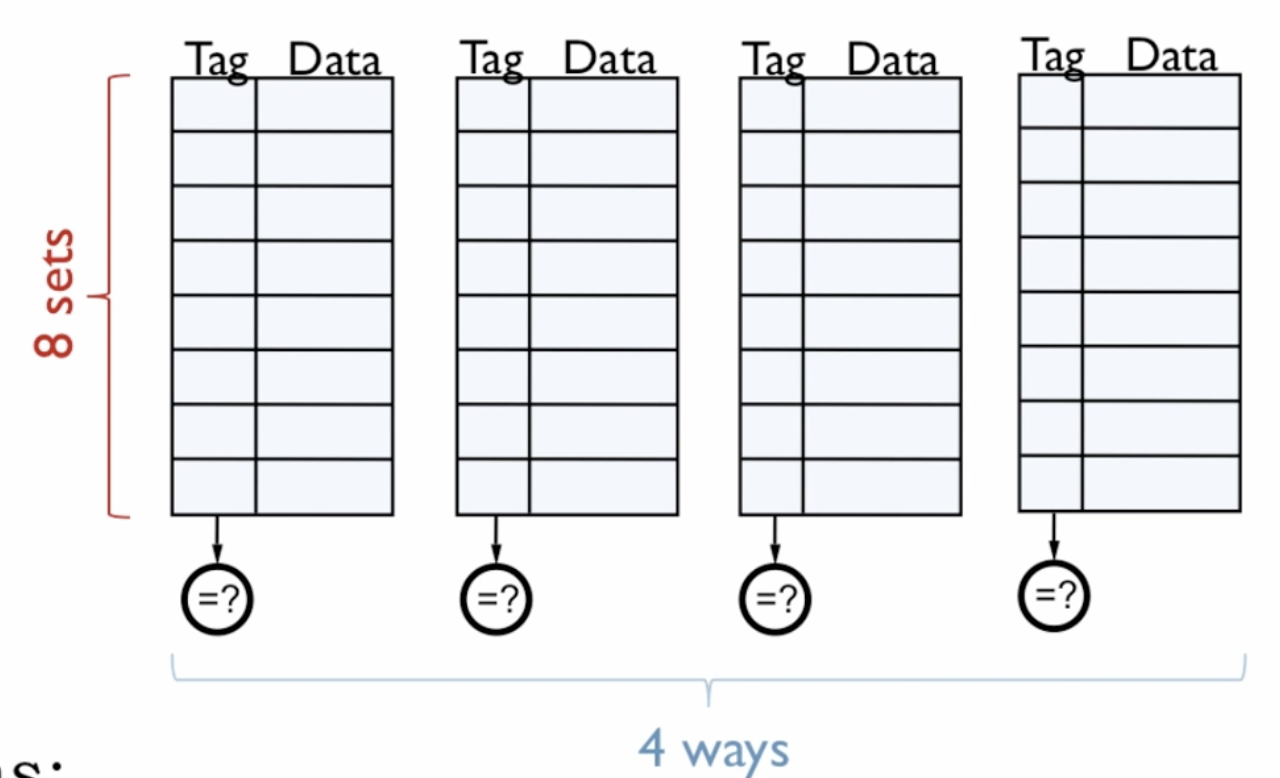
Generally L2 caches use associativity levels of up to 24, while L1 caches get by with 8 sets.
Some questions: Is it possible for a single set to have multiple tag matches? No. If the tag and index match, we are already referring to the same block in physical memory.
Effects of Cache Size, Associativity and Line Size
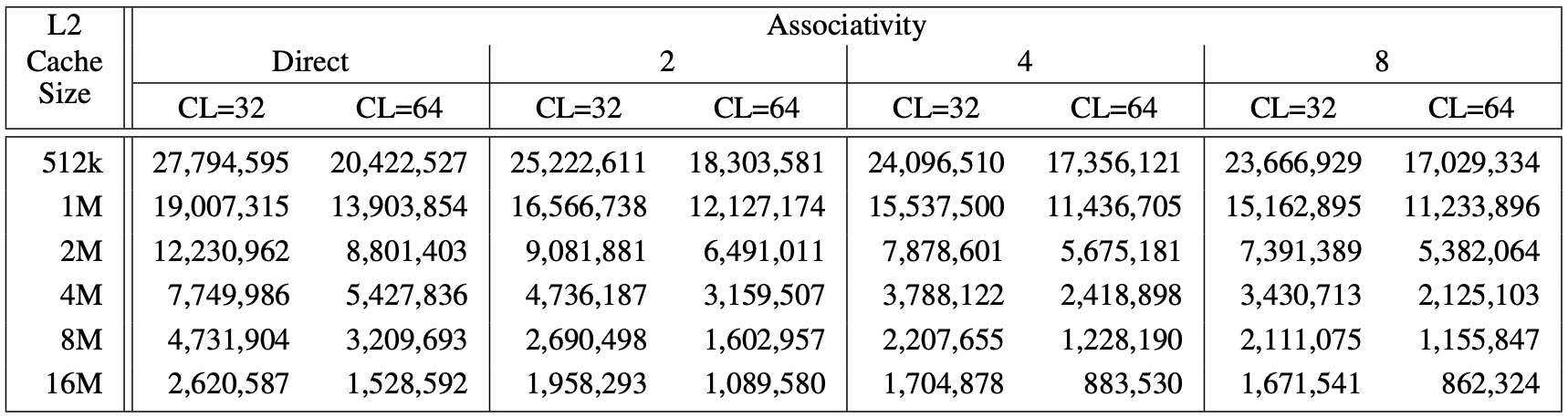
The table shows L2 cache miss counts across varying cache size, associativity, and cache line size. Lower numbers are better.
Cache size has the biggest impact by far. Going from 512k to 16M reduces misses by roughly 10x across all configurations. This is the dominant factor.
Cache line size (CL=32 vs CL=64) consistently matters too. Doubling the line size reduces misses significantly at every cache size and associativity level, because you fetch more spatial neighbors per miss, amortizing the miss cost over more usable data.
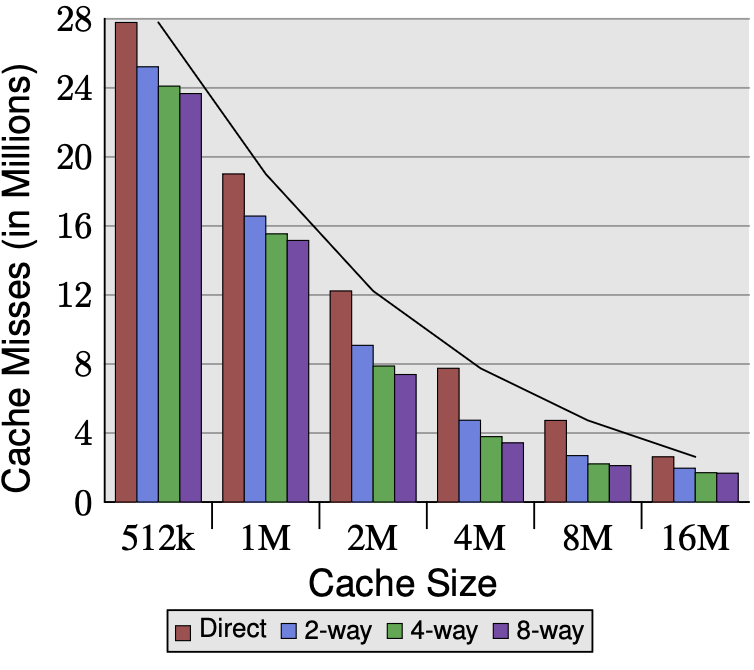
Associativity shows diminishing returns. The jump from direct-mapped to 2-way gives the biggest gain. From 2 to 4, smaller gain. From 4 to 8, almost nothing - look at 8M and 16M rows, the numbers barely budge between 4-way and 8-way. This matches the earlier discussion: at 8M and 16M, the 5.6MB working set fits comfortably, so conflict pressure is already low and more associativity can’t help much.
Associativity only helps when conflict misses are the bottleneck. For small caches where the working set doesn’t fit, more ways reduce conflicts meaningfully. For large caches where it does fit, associativity gains nearly vanish — capacity is the constraint, not conflicts.