Continuation from part 2. This covers cache coherence — what happens when multiple CPUs each have their own cache but share the same memory.
Write-Through vs Write-Back
These are two strategies for keeping cache and main memory in sync when you write data.
Write-through is simple: every write to cache immediately also writes to main memory. Cache and RAM are always identical.
The problem is performance — if you’re incrementing a counter in a loop, every single increment fires a write to main memory over the FSB, even though nobody else needs that value yet.
Write-back is smarter: writes only update the cache line and mark it dirty. The write to main memory is deferred until the cache line gets evicted (LRU etc). A tight loop modifying the same variable fires one eventual write to RAM instead of thousands — much better for FSB bandwidth.
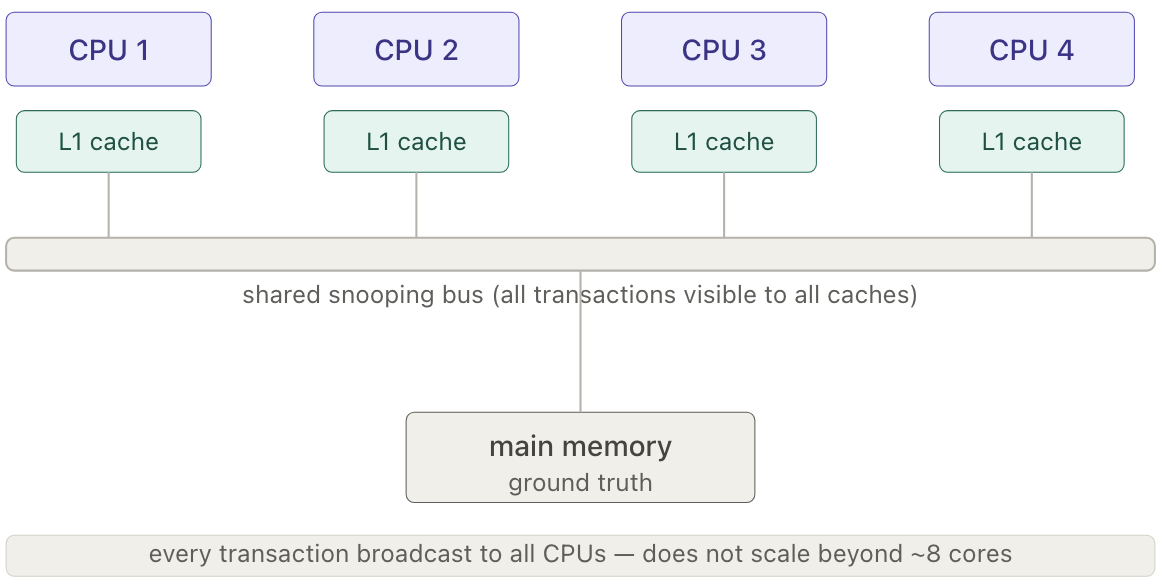
The Problem: Multiple Caches, One Memory
Write-back creates a problem on multi-processor systems. Each CPU has its own cache, so if CPU 1 has a dirty cache line (modified but not yet written back to RAM) and CPU 2 tries to read that same address, CPU 2 fetches from main memory and gets the stale old value. The correct value is sitting in CPU 1’s cache, unreachable.
This is the cache coherence problem. The hardware must solve it: when CPU 2 requests an address, the system needs to know that CPU 1 holds a dirty version and intercept the read to supply the correct data. This is what cache coherence protocols like MESI handle.
The MESI Protocol
Each cache line in every processor’s cache is tagged with one of four states (2 bits are used):
- Modified (M): Present only in this cache, and dirty — it has been modified from the value in main memory. The cache must write the data back to main memory before any other cache can read it. The write-back transitions the line to Shared.
- Exclusive (E): Present only in this cache, but clean — it matches main memory. It may become Shared in response to a read request from another CPU, or Modified when written to locally.
- Shared (S): May exist in multiple caches and is clean — it matches main memory. The line may be discarded (⇒ Invalid) at any time.
- Invalid (I): The cache line is invalid (unused).
For any given pair of caches, the permitted states of a given cache line are:
| M | E | S | I | |
|---|---|---|---|---|
| M | ✗ | ✗ | ✗ | ✓ |
| E | ✗ | ✗ | ✗ | ✓ |
| S | ✗ | ✗ | ✓ | ✓ |
| I | ✓ | ✓ | ✓ | ✓ |
When a line is M or E in one cache, all other caches must hold it as I.
State Transitions
The MESI protocol is a finite-state machine driven by two types of stimuli.
Processor requests — issued by the local CPU:
- PrRd: processor requests to read a cache block
- PrWr: processor requests to write a cache block
Bus-side requests — snooped from other processors via the shared bus:
- BusRd: another processor wants to read a block
- BusRdX: another processor wants to write a block it doesn’t currently hold. The X stands for Exclusive — the requester needs the data and exclusive ownership, so all other caches must invalidate their copies. It’s not called BusWrite because the processor doesn’t have the data yet and must fetch it first; the write comes after.
- BusUpgr: another processor wants to write a block it already holds in Shared state. Since it already has the data, only invalidation is needed — no data transfer, cheaper than BusRdX.
- Flush: a cache is writing a dirty block back to main memory.
- FlushOpt: a cache supplies a block directly to another cache on the bus, bypassing main memory (cache-to-cache transfer). The Opt stands for Optional — main memory may or may not update itself by snooping this transfer. It’s faster because cache-to-cache latency is lower than a round-trip through RAM.
Snooping: every cache monitors all bus transactions. When a bus request appears, each cache controller checks whether it holds that line and reacts — updating state, supplying data, or invalidating its copy. The memory controller also snoops, stepping in when no cache can supply the line.
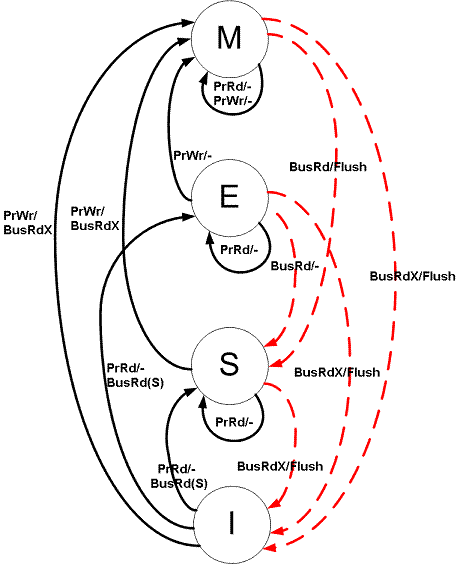
All cache lines start Invalid.
Processor-initiated transitions
| Initial State | Operation | Response |
|---|---|---|
| Invalid | PrRd | Issue BusRd on bus. Others check if they have a valid copy and inform sender. ⇒ S if another cache has a copy; ⇒ E if none (must wait for all to report). Data supplied by another cache or fetched from main memory. |
| Invalid | PrWr | Issue BusRdX on bus. ⇒ M. Others send value if they have it, else fetch from main memory. Others see BusRdX and invalidate their copies. Write into cache block. |
| Exclusive | PrRd | Cache hit — no bus traffic. State remains E. |
| Exclusive | PrWr | Cache hit — no bus traffic. Silent E⇒M upgrade. |
| Shared | PrRd | Cache hit — no bus traffic. State remains S. |
| Shared | PrWr | Issue BusUpgr on bus. ⇒ M. Other caches see BusUpgr and mark their copies Invalid. |
| Modified | PrRd | Cache hit — no bus traffic. State remains M. |
| Modified | PrWr | Cache hit — no bus traffic. State remains M. |
Bus-initiated transitions
| Initial State | Operation | Response |
|---|---|---|
| Invalid | BusRd | No state change. Signal ignored. |
| Invalid | BusRdX / BusUpgr | No state change. Signal ignored. |
| Exclusive | BusRd | ⇒ S (implies a read in another cache). Put FlushOpt on bus with block contents. |
| Exclusive | BusRdX | ⇒ I. Put FlushOpt on bus with block contents. |
| Shared | BusRd | No state change. May put FlushOpt on bus with block contents (design choice — one Shared cache supplies the data). |
| Shared | BusRdX / BusUpgr | ⇒ I (cache that sent BusRdX/BusUpgr becomes Modified). May put FlushOpt on bus with block contents (design choice). |
| Modified | BusRd | ⇒ S. Put FlushOpt on bus with data. Received by sender of BusRd and memory controller, which writes to main memory. |
| Modified | BusRdX | ⇒ I. Put FlushOpt on bus with data. Received by sender of BusRdX and memory controller, which writes to main memory. |
Key insight: E⇒M is silent — a PrWr on an Exclusive line needs no bus transaction. S⇒M requires a BusUpgr broadcast to every CPU holding the line. This is why the CPU tries to keep lines Exclusive — it avoids the broadcast on the next write.
Implications for Performance
A few bottlenecks come up when multiple CPUs share memory.
Coherence protocol latency: A MESI transition can’t complete until every CPU has acknowledged the message — the slowest reply sets the pace. Bus collisions, NUMA latency, and high traffic volume all worsen this. Keep RFOs (Read-For-Ownership) infrequent.
Shared FSB bandwidth: The FSB is a shared resource. If one CPU can saturate it alone, two or four CPUs sharing it each get proportionally less. Even with separate per-CPU buses to the memory controller, concurrent accesses to the same memory module still contend.
Synchronization bandwidth: Even in AMD’s model where each CPU has local memory, multithreaded programs must periodically synchronize through shared memory regions. That traffic competes for the same finite bus bandwidth.
Multithreaded programs need to minimize the number of CPUs touching the same memory — more sharing means more bus traffic and more coherence overhead.